El equipo de Better Innovation Lab participó en un proyecto de investigación DisTEMIST (DISease TExt Mining Shared Task) sobre indexación semántica biomédica a gran escala y respuesta a preguntas. El desafío se centró en el descubrimiento de menciones de enfermedades médicas en textos clínicos en idioma español y el equipo ocupó el segundo lugar en la categoría de términos clínicos relacionados con enfermedades de SNOMED.
La intención del desafío, organizado por Barcelona Supercomputing Center, BioASQ y Plan TL, era encontrar y desarrollar formas automatizadas de descubrir información relevante en los datos, expandir dicha información con conocimiento del dominio y ofrecer estructura a la información. El desafío de este año se centró en el descubrimiento de menciones de enfermedades médicas en textos clínicos. Los organizadores proporcionaron un conjunto de documentos clínicos y pidieron a los equipos que idearan una solución que comprendiera el contenido de los documentos, reconociera las menciones de las enfermedades y luego vinculara esas enfermedades a los términos clínicos de SNOMED.
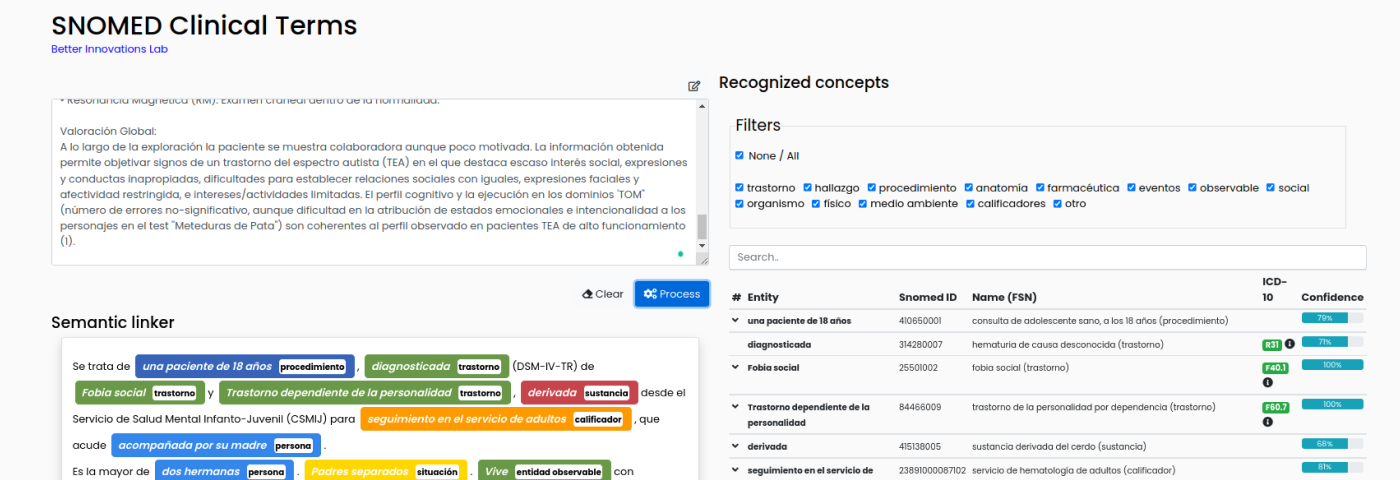
En el desafío, los equipos tenían que desarrollar una solución que constaba de dos componentes principales, uno que abordara el problema de comprensión del idioma español y el segundo que relacionara las enfermedades descubiertas con los términos clínicos de referencia de Snomed.
El equipo desarrolló un enfoque utilizando "incrustaciones de vectores" para transformar textos clínicos
El equipo Better, Robert Tovornik y Matic Bernik, junto con Luis Marco Ruiz de Norwegian Center for E-health Research, utilizaron un marco, que ya ofrece un modelo en español, y cambiaron el enfoque en la tarea de reconocer las enfermedades. Utilizaron el conjunto de datos para entrenar un modelo NER (reconocimiento de entidad nombrada) que tiene el poder de identificar elementos y patrones clave en el texto y localizar entidades en cuestión, en este caso, enfermedades clínicas. Lo hace procesando y comprendiendo grandes cantidades de datos estructurados y no estructurados. Agregaron algunos trucos y ajustes propios para mejorar el rendimiento y asegurar un modelo de reconocimiento de enfermedades competente.
La segunda parte del desafío, la combinación de términos clínicos, es donde el equipo realmente brilló. Han desarrollado su propia solución que es a la vez precisa y extremadamente rápida, superando las velocidades de los servicios de PNL de Amazon o Microsoft. Han establecido un modelo que transforma todos los textos, tanto las enfermedades clínicas descubiertas como las descripciones de términos, sinónimos, etc. de Snomed, en vectores numéricos a través de un proceso llamado “Incrustaciones de vectores”. Después de eso, utilizaron una base de datos de vectores Milvus descubiertos recientemente para almacenar los vectores y ejecutar comparaciones rápidas en la parte superior para encontrar sus coincidencias de alta confianza.
El proceso de innovación fue bastante rápido y como dijo Robert Tovornik, científico de datos de Better, “nada de esto hubiera sido posible sin una estrecha colaboración con nuestro querido colega Luis Marco Ruiz. Él fue quien, después de una breve demostración por nuestra parte, se aferró a la idea y nos presentó el desafío DISTEMIST. A lo largo del desafío, nos ofreció un valioso apoyo, comentarios y una visión extremadamente importante del idioma español”.
![full-example-2[41]](https://news.better.care/hs-fs/hubfs/full-example-2%5B41%5D.png?width=1815&name=full-example-2%5B41%5D.png)
La solución como parte de plataforma Better
Como esta es una gran innovación para Better, hay planes para incluir la solución como parte de plataforma Better. Lo más probable es que comience con la versión en inglés, no como un servicio independiente, sino como parte de un servicio más amplio o como complemento de Archetype Designer y Studio. “Encaja bien con los principios de almacenamiento de datos de manera organizada, ampliando la funcionalidad al formato de texto libre no estructurado. Sin embargo, son posibles otras implementaciones, por ejemplo, una herramienta de anotación para los desarrolladores interesados en preparar datos de forma semiautomática para sus soluciones de modelo personalizadas”, dijo Robert Tovornik.
“El logro valida la importancia de la buena colaboración, el trabajo en equipo y la innovación. Trae una pequeña victoria para que el equipo la celebre, lo que con las innovaciones puede ser raro, ya que generalmente no se sabe el resultado claro que se avecina. Y, sobre todo, trae una confirmación de que estamos yendo en la dirección correcta, junto con un impulso de motivación”, también dijo Robert y agregó que espera con ansias más desafíos como este.
Puede conocer más sobre la competencia aquí.